Shruti Bhargava
I am a Senior ML Research Engineer working on conversational AI in Apple's Siri Core Modeling team, where I develop advanced language understanding systems and LLM response strategies. I completed my Masters in Computer Science from the University of Illinois at Urbana-Champaign (UIUC), advised by Prof. David Forsyth, and my Bachelors from IIT Kanpur, India.


Apple Inc.
2019 - Present

UIUC
2017 - 2019
Apple Inc.
2018 Summer

CSL
2017 Fall

Microsoft Research
2016 Summer

Max Planck Institute
2015 Summer

IIT Kanpur
2013 - 2017
Patents
- Digital Assistant Reference Resolution - US Patent
H Yu, S Adya, S Bhargava, M Lukens, J Cheng, L Li, A Patel, D Piraviperumal, SG Pulman - Digital Assistant Intelligence Engine - US Patent Application
A Aggarwal, C Sumanth, CS O'Mara, H Yu, KM Daryanani, LN Perkins, NL Tzou, N Rajshree, S Kohli, S Bhargava - Virtual Object Placement Based on Referential Expressions - US Patent Application
A Patel, S Adya, S Bhargava, A Blechschmidt, V Nair, A Polichroniadis, K Sandridge, D Ulbricht, H Yu
Publications

SynthDST: Synthetic Data is All You Need for Few-Shot Dialog State Tracking
Atharva Kulkarni, Bo-Hsiang Tseng, Joel Ruben Antony Moniz, Dhivya Piraviperumal, Hong Yu, Shruti Bhargava
EACL (Oral) 2024
Data generation framework that can efficiently generate synthetic data for dialogue schemas using countable templates. This bridges the gap between zero-shot and training data based few-shot prompting for dialog state tracking with LLMs.

Can Large Language Models Understand Context?
Yilun Zhu, Joel Ruben Antony Moniz, Shruti Bhargava, Jiarui Lu, Dhivya Piraviperumal, Site Li, Yuan Zhang, Hong Yu, Bo-Hsiang Tseng
EACL Findings 2024
A benchmark by adapting four tasks and nine existing datasets, featuring prompts designed to assess the context-understanding abilities of LLMs. In the ICL setting, models struggle with understanding nuanced contextual signals compared to SOTA fine-tuned models. Assessment of quantized models provides promising insights on the 3-bit post-training quantization.

Referring to Screen Texts with Voice Assistants
Shruti Bhargava, Anand Dhoot, Ing-Marie Jonsson, Hoang Long Nguyen, Alkesh Patel, Hong Yu, Vincent Renkens
ACL Industry Track 2023
Novel experience for users to refer to data-detectable entities on their phone screens when interacting with voice assistants. Screen reference resolution data strategy and a lightweight, general-purpose model that only uses the text extracted from the UI. The proposed model is modular, offering flexibility, better interpretability, and efficient run-time performance.
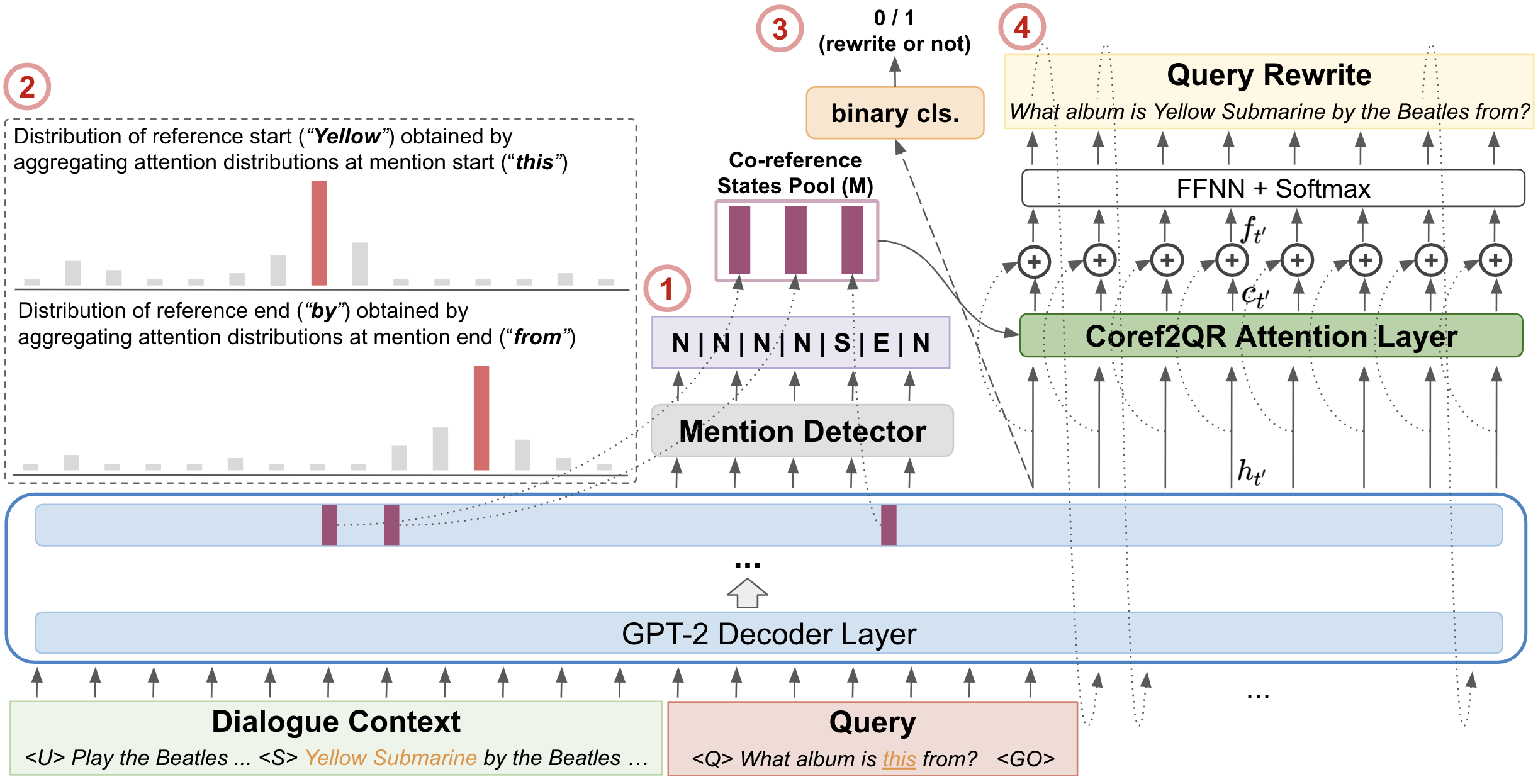
CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues
Bo-Hsiang Tseng, Shruti Bhargava, Jiarui Lu, Joel Ruben Antony Moniz, Dhivya Piraviperumal, Lin Li, Hong Yu
NAACL 2021
[code]
Resolving references and understanding ellipses are crucial for dialogue agents to generate coherent responses. A joint benchmark for the two tasks by annotating the dialogue-based coreference dataset, MuDoCo, with rewritten queries. A novel joint learning framework that boosts query rewrite and outperforms SOTA for coreference resolution.

Conversational semantic parsing for dialog state tracking
Jianpeng Chen, ... , Shruti Bhargava, ... , Jason D Williams, Hong Yu, Diarmuid O Seaghdha, Anders Johannsen
EMNLP 2020
[Dataset]
Fresh perspective on dialog state tracking as a semantic parsing task over hierarchical representations, with compositionality, cross-domain knowledge sharing, and coreference. We present TreeDST, a dataset of 27k conversations with tree-structured states and system acts. Our encoder-decoder model leads to a 20% improvement over SOTA.

Exposing and Correcting the Gender Bias in Image Captioning Datasets and Models
Shruti Bhargava, David Forsyth
arxiv 2019
The task of image captioning implicitly involves gender identification. MS COCO dataset contains blatant gender bias in captions, arising from two main sources: statistical variation in data and flawed annotations. Biased data leads to concerning predictions by models. We propose a novel framework for gender-neutral captioning and independent gender classification using masking, reducing contextual bias. On an anti-stereotypical dataset, our approach outperforms the SOTA gender-based approaches.
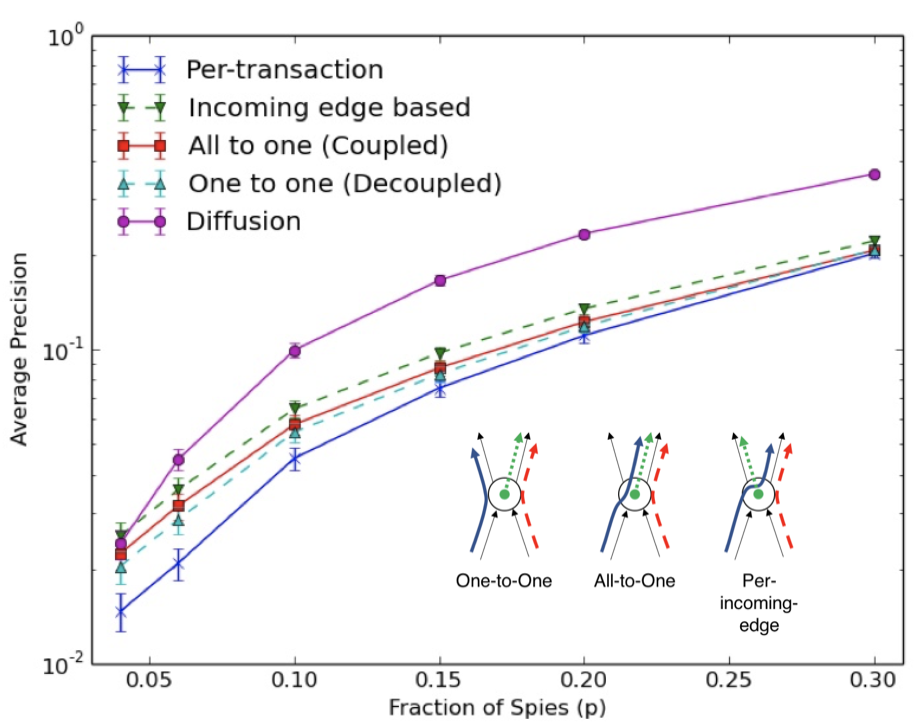
Dandelion++ lightweight cryptocurrency networking with formal anonymity guarantees
Giulia Fanti, Shaileshh Bojja Venkatakrishnan, Surya bakshi, Bradley Denby, Shruti Bhargava, Andrew Miller, Pramod Viswanath
SIGMETRICS 2018
[code]
Bitcoin's networking stack is shown to have anonymity vulnerabilities owing to the mechanism for broadcasting transactions, leading to large-scale deanonymization attacks. We present Dandelion++, a first-principles defense with near-optimal information-theoretic guarantees.
Mentorship Experience
- Le Zhang, Ph.D. - Mila - Quebec AI Institute (Summer 2025) - Spatial Thinking in Multimodal LLMs
- Atharva Kulkarni, MS - CMU (Summer 2023) - Bridging the gap between Zero and Few-shot DST
- Yilun Zhu, Ph.D. - Georgetown University (Summer 2023) - Context Understanding in Quantized LLMs
- Soundarya Krishnan, MS - CMU (Summer 2021) - Grounding in Visual Memory for Multimodal Assistant
- Bo-Hsiang Tseng, Ph.D. - University of Cambridge (Summer 2020) - Ellipsis and Anaphora in Dialogues
- Sahana Mohandoss, Rotation Engineer - Apple (Fall 2021) - Data-efficient Screen Reference Resolution
Awards and Scholarships
- Best Paper Award for "CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues", WeCNLP 2021
- Grace Hopper Student Scholarship, Anita Borg Institute
- Academic Excellence Award, IIT Kanpur
- National Talent Search (NTS) Scholarship, Government of India
- KVPY Fellowship, Department of Science and Technology, Government of India
Teaching
I have served as a Teaching Assistant for graduate and undergraduate courses spanning optimization, machine learning, algorithms, and programming:
- CS544: Optimization in Vision and AI at UIUC [Spring 2019]
- CS498: Applied Machine Learning at UIUC [Fall 2018]
- CS374: Algorithms and Models of Computation at UIUC [Spring 2018]
- CS101: Introduction to Programming at IIT Kanpur [Spring 2017]
Academic Research
During my academic journey, I had the opportunity to collaborate with inspiring researchers across leading institutions.
- Fall 2017: Coordinated Science Laboratory, UIUC with Prof. Pramod Viswanath
- Fall 2016: IIT Kanpur with Prof. Purushottam Kar
- Summer 2016: Microsoft Research with Dr. Nagarajan Natarajan
- Summer 2015: Max Planck Institute for Informatics with Prof. Kurt Mehlhorn and Dr. Geevarghese Philip